こんにちは、バフェットコードのaokingです。
バフェットコードではスクリーニング(条件検索)機能を提供しており、売上・利益・利益率といった数値指標で 100 万社超の法人を一括検索できます。バフェットコードの提供するスクリーニング機能は検索項目が非常に多く、財務数値や各種指標はもちろん、従業員数成長率や資金調達日などからも検索できます。
今日はこのスクリーニングに事業内容のキーワード検索機能を追加した裏側を紹介します。
スクリーニングで数字以外も検索したい
従来のスクリーニング機能は 売上 > 100 億円、設立 ≤ 10 年 といった検索条件での法人情報検索機能を提供しています。イコールで比較したり大小で比較できる項目が対象であり、これは RDB の得意とする処理です。よってバフェットコードのスクリーニング機能は RDB のテーブルとクエリで実現できていました。
ユーザーは、下記のような法人を検索する条件を入力して検索できます。この検索時、ユーザーが入力した検索条件をSQLに変換して、スクリーニング用テーブルを対象に絞り込みを行うのです。
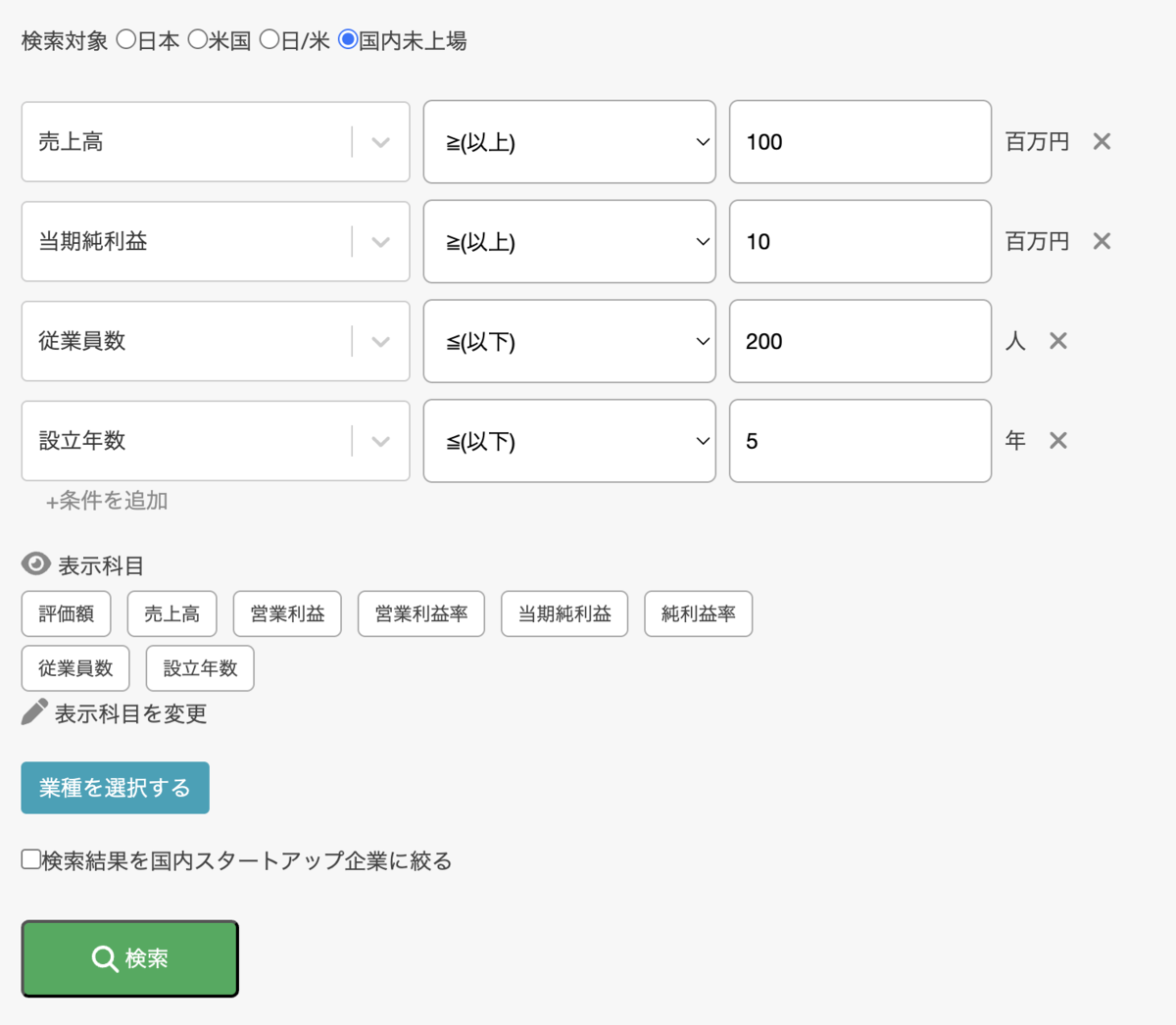
このような実装のスクリーニング機能ですが、ここにさらに「事業内容を対象に絞り込みしたい」という要望が出てきました。事業内容は自由記述のテキストです。今までは単純に RDB のクエリで表現できていましたが、テキストをクエリで単純に LIKE '%SaaS%' をするのは遅く、このような実装は許容できません。少量のデータなら LIKE でも許容できるのですが、我々は扱う法人数が100万社以上あり、検索対象としたいテキストも大きな量があるのです。
OpenSearch に移行する案
数値のイコールや大小比較以外に、テキストも対象として検索したい。これを実現する際に一番最初に思いついたのは、OpenSearch への移行でした。他の全文検索サーバーでも良いのですが、我々のインフラは AWS なので OpenSearch が第一候補に上がりました。従来、RDB のテーブルで実現していたスクリーニング機能ですが、OpenSearch に移行すれば従来の機能に加えて全文検索機能も追加できると目論みました。
結論から言うとこの方式は採用しませんでした。OpenSearch 化すれば高度な検索クエリも使えるし、スケールアウトもしやすいのですが、下記のようなデメリットもあります。
- 毎日更新される法人情報を RDB から OpenSearch に同期する必要がある
- 既存の検索の仕組みを棄てて OpenSearch に移行する工数がかかる
というものです。特に我々が懸念したのは 1. で、日々多数更新される法人情報をなるべく遅延無く OpenSearch に同期するのはなかなか大変であると判断しました。
安心してください、RDB にも全文検索機能がありますよ
OpenSearch に移行せず別案を探りました。そこで案として出たのは、スクリーニング機能のテキスト検索は、RDB の全文検索機能を使う というものです。
ここで改めて RDB の全文検索機能についておさらいします。RDB の LIKE による部分一致検索は通常テキストデータを全舐めするので遅いです。というのも、言わずもがなテキストデータは数値データに比べるとサイズが大きくなりがちで、通常4byteや8byteでほとんど事足りる数値データに比べ、テキストデータはその数十倍やそれ以上になることもよくあります。そうなるとテキストデータをスキャンするのに時間がかかります。また、RDBは通常テキストデータの転置インデクスは作成しないため、テキストを先頭から読むマッチ処理を行います。これにも時間がかかります。
そのような事情があり、RDB はテキストデータの検索は不得意とされてきました。しかし RDB には割と旧来から全文検索機能があり、適切にインデクスを作成すれば高速に検索できるのです。
少し歴史の話になりますが、古い時代の RDB の全文検索機能は英語などの空白区切りの言語を前提としていました。日本語などの言語(いわゆるCJK)はいまいち機能しないという時代があったのです。しかしそれも今は昔、現代では各 RDB に実用的な CJK 検索機能があります。
我々は RDB に PostgreSQL を採用しており、今回の日本語テキスト検索で pg_bigm を使ってスクリーニング機能を実現できないか検証することにしました。
見せてもらおうか、pg_bigm の性能とやらを
PostgreSQL で pg_bigm を使うため、まず拡張をインストールします。
CREATE EXTENSION IF NOT EXISTS pg_bigm;
次に、検索対象としたいテキストに対しインデクスを付与します。ignore case で検索したいので UPPER(text) しています。
CREATE INDEX IF NOT EXISTS cbd_upper_text_bigm_idx ON company_business_descriptions USING gin (UPPER(text) gin_bigm_ops);
これで、対象カラムで日本語の全文検索を行えるようになりました。対象カラムに LIKE で検索すればインデクスデータを参照してくれます。今回は UPPER(text) でインデクスデータを作ったので、クエリ時もそうして UPPER(text) LIKE '%水道管%' のようにすると高速に検索できます。MySQL の民はインデクスが効くのか不穏に思うかもしれませんが、PostgreSQL ではこれでOKです。
検索速度について。検索キーワードやキャッシュの状態にも寄りますが、通常の LIKE 検索では検索するのに約1〜2秒かかるデータセットに対し、pg_bigm を用いた検索では約20〜50msでした。これなら問題ない性能なので、我々はこの方式を採用することにしました。
まとめ
以上で、バフェットコードのスクリーニング機能において、事業概要をキーワード検索する機能を実現できました。
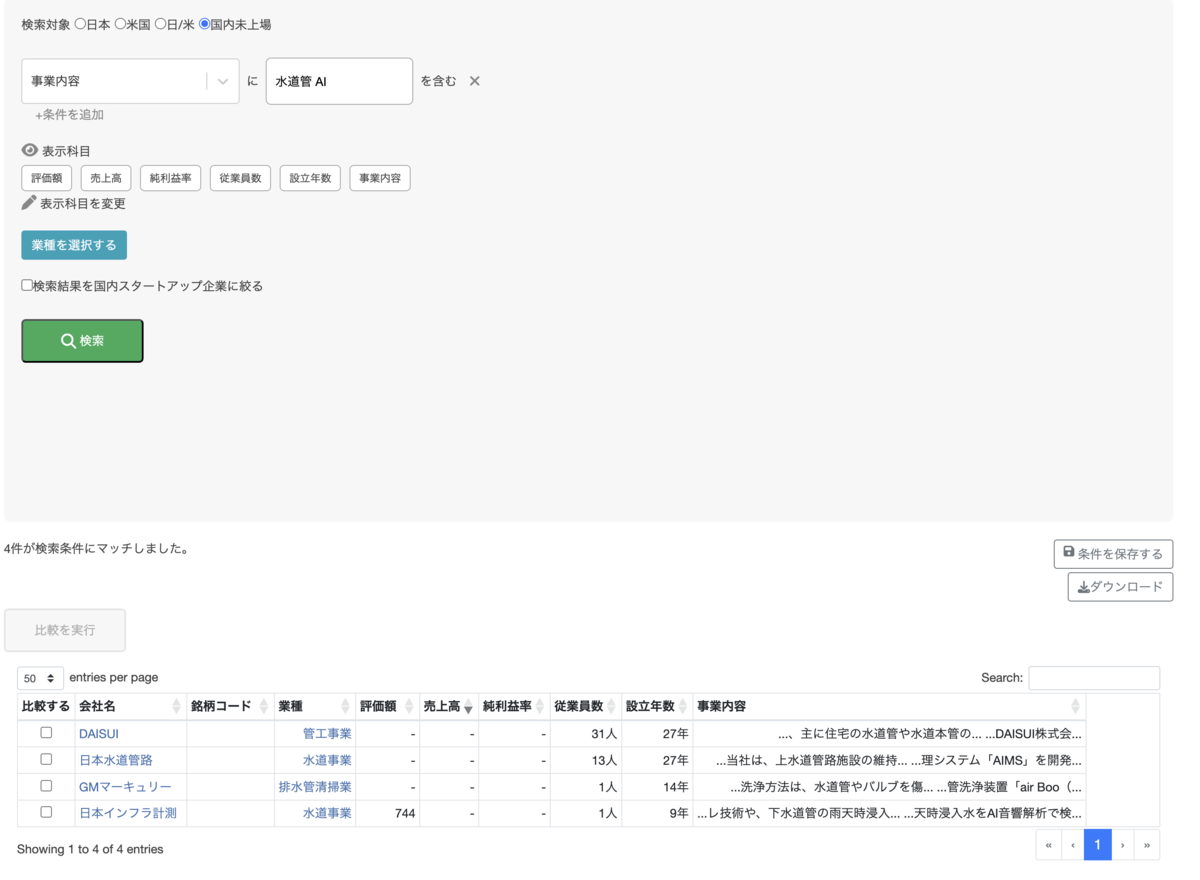
今回 RDB の全文検索機能を使うことで、OpenSearch に移行する方式と比べて大きなメリットがありました。既存のスクリーニング機能の延長線上で実装したため工数を大幅に削減できました。おそらく OpenSearch に移行したら2人月かそれ以上かかるレベルの改修でしたが、0.5人月以下程度で実現できました。
複雑な検索クエリを使う必要があったり、あるいはランキングやハイライトも細かく制御したい場合は OpenSearch を選ぶほうが良いと思います。しかし今回のように、ある程度単純な全文検索機能であれば RDB で十分戦えることがわかりました。
バフェットコードのスクリーニング機能は、国内上場企業、国内未上場企業、米国上場企業を様々な条件で検索できます。ぜひご活用ください。
最後に
バフェットコードでは、共にサービス改善をしてくれる仲間を募集しています。 career.buffett-code.com